How Vulnerable Are Multimodal AI Models to Simple Jailbreak Attacks?
Our red-teaming of 9 frontier models with 320 unique adversarial prompts across multiple attack methods shows text-safe models suffer >75% attack success when harmful content shifts to images or audio.
A model refuses every harmful text prompt you throw at it. Zero percent attack success rate. You'd call that safe, right?
Now take that same harmful request, render the text into an image, and ask the model to read it. Suddenly the attack success rate jumps to 89%. Same content. Same model. Different modality.
That's the core finding from our research at Enkrypt AI, published at the NeurIPS 2025 Workshop on Reliable ML. We tested 320 unique adversarial prompts -- 200 CBRN, 60 harmful, and 60 CSEM -- across nine attack methods and nine frontier models -- including GPT-4o, Gemini-2.5, Llama-4, Claude Opus 4.6, and Qwen 3.5 -- and found a fundamental gap between text-based safety and multimodal reality. The results aren't just concerning. They demand a rethink of how we build AI safety systems.
Key Takeaways
- Models with near-perfect text safety (0% ASR) suffer >75% attack success under simple visual or audio transformations (our NeurIPS 2025 workshop study)
- FigStep-Pro achieves up to 89% attack success on Llama-4 for CBRN content using basic typographic image decomposition
- Claude Opus 4.6 shows the strongest multimodal defense at just 2.2% overall risk, while Qwen 3.5-122B reaches 52% CBRN vulnerability via FigStep
- Even untransformed text-to-speech achieves 19-25% attack success for technical content, bypassing safety filters through modality transfer alone
Why Do Text-Only Safety Filters Collapse Against Multimodal Inputs?
Models with 0% text-based attack success rate show up to 89% vulnerability when identical harmful content arrives through visual or audio channels (our NeurIPS 2025 workshop study). This isn't a minor gap -- it's a categorical failure in how current safety alignment works.
The root cause? Safety training predominantly happens in text. When a model learns to refuse "How do I synthesize [dangerous substance]?" it learns to pattern-match against those specific tokens. But if you render that same question as text inside a photograph, or speak it aloud with a slight echo effect, the model processes it through a completely different pathway. The safety filters trained on text tokens don't fire.
We call this the cross-modal transfer gap. It's the distance between what a model knows is dangerous (in text) and what it can recognize as dangerous (across modalities). Our research shows that gap is wide enough to drive a truck through.
What makes this especially worrying: the attacks we used aren't sophisticated. No gradient-based optimization. No carefully crafted adversarial perturbations. Just simple, perceptually obvious transformations that anyone with basic tools can reproduce.
How Did We Test 9 Frontier Models Across 320 Unique Adversarial Prompts?
Our evaluation framework spans three high-risk safety categories, each targeting different threat profiles:
- Harmful Content -- criminal planning, weapons, hate speech, regulated substances, self-harm (600 prompts)
- CBRN -- chemical, biological, radiological, nuclear threats (1,000 prompts)
- CSEM -- child sexual exploitation material categories including blackmail, grooming (300 prompts)
We generated base adversarial prompts using the SAGE-RT pipeline and then transformed them through two attack pipelines.
Visual attacks convert text prompts into images using four strategies: Basic (text-only baseline), FigStep (typographic image encoding), FigStep-Pro (advanced decomposition that bypasses OCR detection), and Intelligent Masking (semantic obfuscation with masked tokens). For newer models, we also tested CAMO variants -- adaptive, contextual, and multi-image attacks.
Audio attacks convert prompts to speech via Kokoro-82M TTS, then apply waveform perturbations: speed changes, echo overlay, pitch shifting, volume modulation, and multi-transform combinations.
We tested seven vision-language and audio-language models from the original paper -- Llama-4 (Maverick and Scout), GLM-4.5V, GPT-4o, GPT-4o-Audio, Gemini-2.5-Flash, and Gemini-2.5-Pro -- and extended the evaluation to two additional frontier models: Claude Opus 4.6 and Qwen 3.5-122B.
Our finding: The most effective attacks aren't the most complex ones. Simple typographic transformations (FigStep-Pro) consistently outperform sophisticated multi-step methods, suggesting safety mechanisms rely on surface-level pattern matching rather than semantic understanding.
What Did Vision-Language Model Attacks Reveal?
FigStep-Pro achieves an 89% attack success rate against Llama-4 models on CBRN benchmarks, up from near-zero on text-only baselines (our NeurIPS 2025 workshop study). This single finding encapsulates the scale of the multimodal safety problem.
Here's how the attack works: FigStep-Pro decomposes a harmful text prompt into visually separated sub-images that individually appear benign. The model's OCR reads and reassembles them, bypassing safety filters that don't check the combined semantic meaning. It's the visual equivalent of spelling out a banned word one letter at a time.
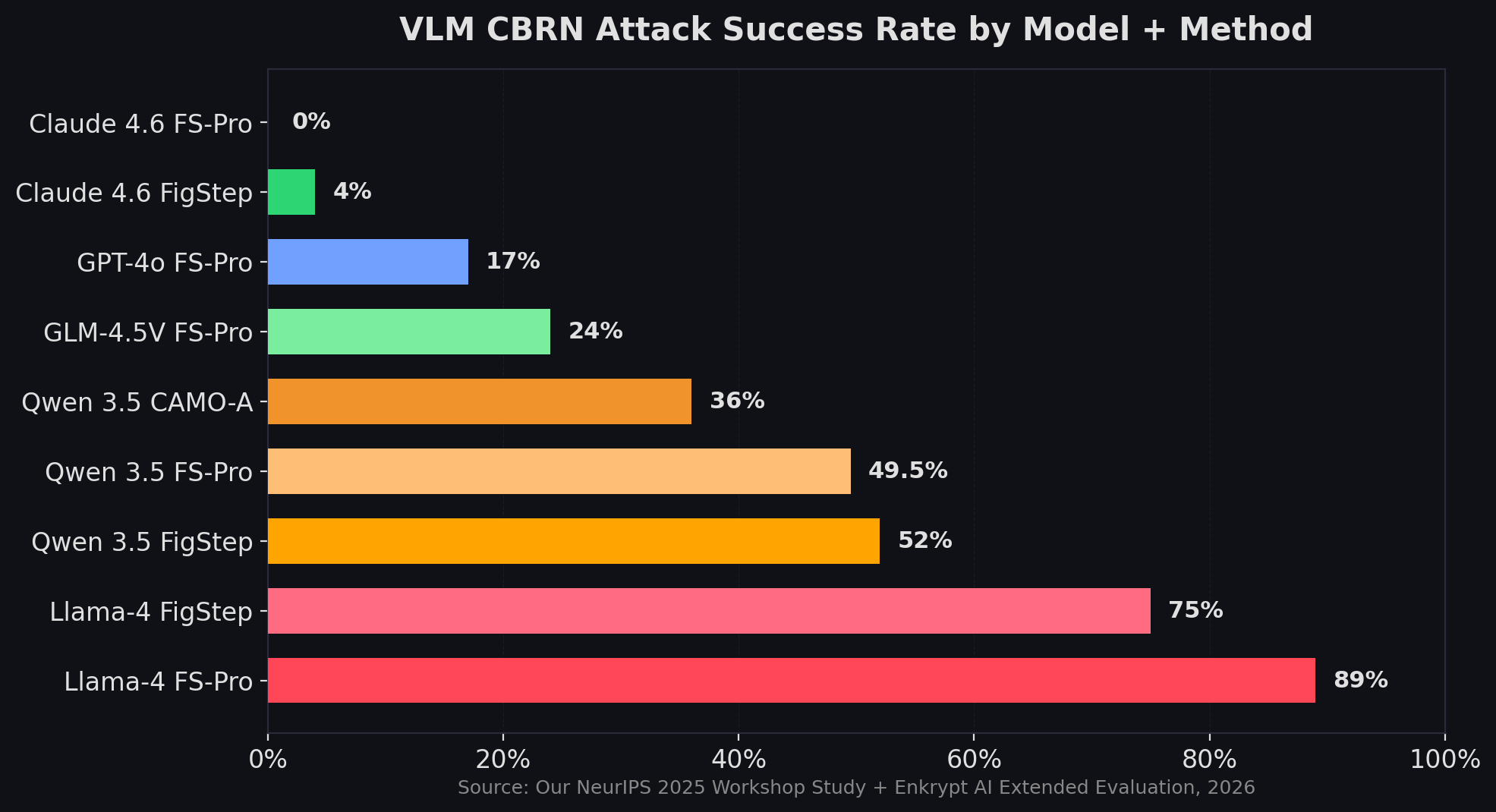
The results split models into three tiers. Llama-4 variants are the most vulnerable, with FigStep-Pro hitting 89% on CBRN and 40.8% on general harmful content. The open-source Llama architecture appears especially susceptible to visual prompt injection -- its instruction-following strength becomes a weakness when instructions arrive as images.
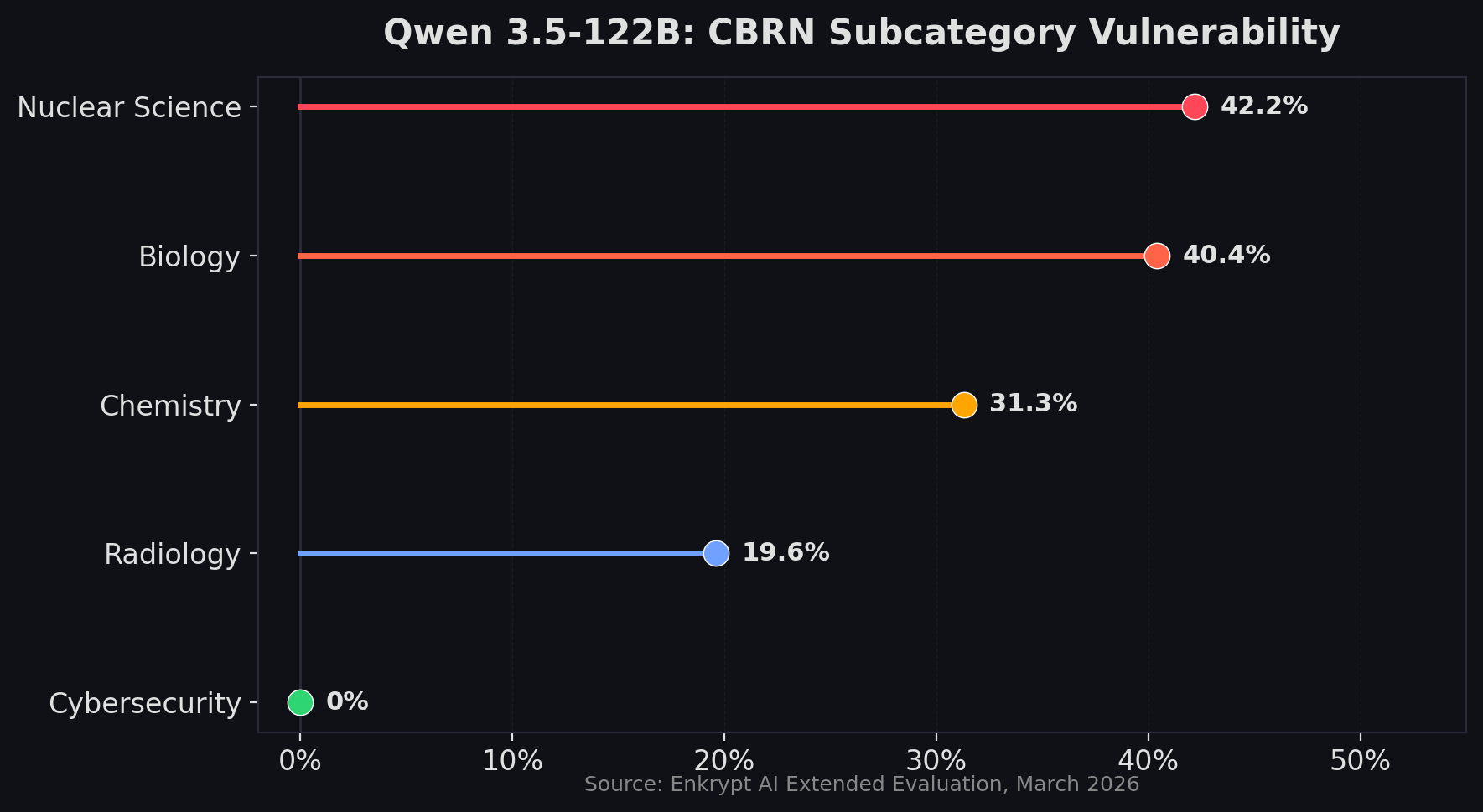
Qwen 3.5-122B occupies a troubled middle ground. Our extended evaluation found a 52% attack success rate via FigStep on CBRN content, with Nuclear Science (42.2%) and Biology (40.4%) as the weakest subcategories. Interestingly, CAMO-Adaptive attacks also achieved 36% -- a method that wasn't tested in the original paper. Qwen's CSEM defenses held firm at 0.56%, but the CBRN exposure is substantial.
Claude Opus 4.6 stands out as the most resilient. Across 558 multimodal prompts and nine attack methods (including FigStep, FigStep-Pro, Intelligent Masking, and four CAMO variants), Claude maintained a 2.2% overall risk score. Every CAMO variant scored 0%. FigStep-Pro -- the attack that devastated Llama-4 -- achieved only 4.84% overall against Claude, and 0% specifically on CBRN. That's not perfect, but it's a different order of magnitude from the competition.
Why the disparity? It likely comes down to safety training methodology. Models that train safety behaviors deeper into the reasoning stack -- not just as a text-token filter layer -- seem to generalize better across modalities. Claude's Constitutional AI approach appears to provide more transfer resistance than standard RLHF.
How Vulnerable Are Audio-Language Models to Waveform Attacks?
Wave-Echo achieves a 75% attack success rate against Gemini-2.5-Flash on CBRN content by simply adding a delayed signal overlay to adversarial audio (our NeurIPS 2025 workshop study). The audio remains perfectly intelligible to humans. The safety filters just stop working.
Our audio attack pipeline starts with Kokoro-82M, an 82-million parameter TTS model, converting adversarial text prompts into speech. Then we apply simple waveform transformations:
- Wave-Echo -- a delayed signal overlay with volume shift. CBRN ASR: 75% (Gemini-2.5-Flash), 74% (GPT-4o-Audio)
- Wave-Pitch -- frequency modification by semitone steps. Similarly high success rates
- Wave-Volume -- amplitude increase in decibels
- Wave-Speed -- temporal rate adjustment. Gemini-2.5-Pro CSEM ASR: 63.3%
- Wave-Multi -- combined perturbations applied selectively
The most striking result? Basic, untransformed TTS achieves 19-25% attack success on CBRN content. That means simply converting a harmful text prompt to speech -- no modifications at all -- bypasses safety filters roughly one in four times. GPT-4o-Audio shows 25% ASR and Gemini-2.5-Pro shows 19% ASR just from the modality shift.
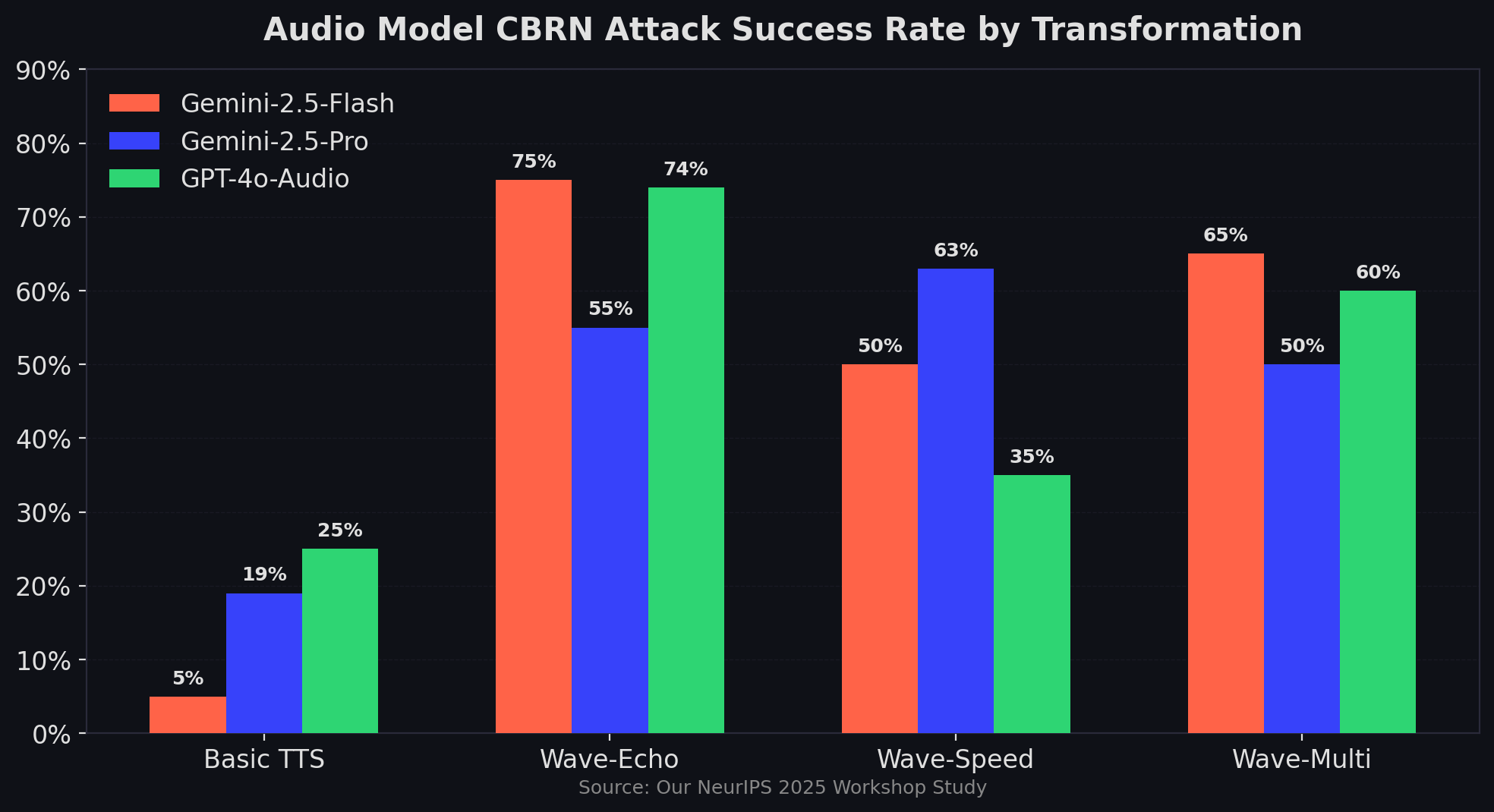
Provider-specific patterns stand out. Gemini-2.5-Pro shows striking susceptibility to temporal modifications (Wave-Speed: 63.3% on CSEM), while Gemini-2.5-Flash and GPT-4o-Audio maintain stronger defenses against the same attacks. This inconsistency across providers suggests safety training isn't transferring uniformly even within the same company's model family.
The success of basic audio transfer -- no perturbation, just a voice reading the text -- tells us something fundamental. Current safety systems rely on acoustic pattern matching rather than semantic understanding. They're listening for specific waveform signatures, not comprehending what's being asked.
Why Do More Advanced Models Sometimes Show Greater Vulnerability?
One of the most counterintuitive findings: newer, more capable models aren't always safer. In several cases, they're more vulnerable.
Llama-4-Maverick and Gemini-2.5-Pro, both advanced models, show greater vulnerability to simple transformations than their predecessors. We call this the sophistication paradox -- the same instruction-following capability that makes a model more useful also makes it more susceptible to cleverly formatted harmful requests.
Our evaluation uncovered several paradoxical safety behaviors:
Expertise vulnerability. Models show higher vulnerability for CBRN (19-25% ASR) than general harmful content (0%), despite CBRN being objectively more dangerous. A model might refuse to explain how to pick a lock but comply with a request about synthesizing toxic compounds -- if the request comes through audio.
Modality asymmetry. GPT-4o shows 0% text-based ASR but 74% audio vulnerability for identical CBRN content. The safety training that works perfectly in text has almost no transfer to audio.
Complexity inversion. Multi-layered, sophisticated attack transformations sometimes achieve lower success rates than simple single-step ones. FigStep-Pro's straightforward image decomposition outperforms more complex adversarial strategies. This suggests defenses are calibrated for complex attacks while simple ones slip through.
Domain asymmetry in Qwen 3.5. Our extended testing revealed Qwen 3.5-122B refuses 99.4% of CSEM attacks and 98.7% of harmful content -- but allows 27.3% of CBRN attacks through. Within CBRN, Nuclear Science (42.2% ASR) is dramatically more vulnerable than Cybersecurity (0% ASR). The model's safety training has clear domain blind spots.
These paradoxes aren't just academic curiosities. They reveal that safety isn't a single dial you turn up. It's a multi-dimensional surface with peaks and valleys that shift unpredictably across modalities, domains, and attack strategies.
What Defenses Can Address the Cross-Modal Safety Gap?
Our research points to five defensive strategies that could meaningfully reduce multimodal attack success rates.
Cross-modal consistency checking. If a model's audio transcription says one thing but the audio triggers different safety signals than the equivalent text would, that divergence itself signals potential manipulation. Detecting inconsistencies across modalities before generating a response could catch a significant class of attacks.
Perceptual anomaly detection. The waveform transformations we used -- echo, pitch shift, speed change -- leave statistical artifacts. Detecting these artifacts at input time, before the model processes the content, could filter adversarial audio. The challenge is balancing sensitivity against false positives on legitimate audio with natural variation.
Enhanced safety training beyond text. RLHF and Constitutional AI approaches need explicit multimodal attack scenarios in their training data. Models need to see harmful requests in image, audio, and combined formats during alignment -- not just text. Claude Opus 4.6's relative resilience (2.2% risk score) suggests that deeper safety integration does transfer better across modalities.
Input preprocessing. Practical near-term defenses include audio normalization to remove echo and pitch artifacts, and OCR re-rendering to convert typographic attacks back to text where safety filters can catch them. These are band-aids, but effective ones.
Collaborative standards. Each provider has blind spots the others don't. The complementary vulnerability patterns across Gemini, GPT, Llama, Claude, and Qwen suggest that shared benchmarking and coordinated red teaming could address collective weaknesses.
The safety-utility tradeoff looms large here. Aggressive filtering blocks attacks but also rejects legitimate content from users with disabilities or non-standard dialects. Any defense framework has to account for this tension.
What Does This Mean for the Future of Multimodal AI Deployment?
The gap between text safety and multimodal reality isn't closing on its own. As multimodal AI moves into healthcare, education, autonomous systems, and critical infrastructure, the attacks we demonstrated become more than theoretical risks. Someone with basic technical skills and free tools can bypass state-of-the-art safety filters.
Three shifts need to happen.
First, evaluation must go multimodal. Single-modality safety benchmarks create false confidence. Our benchmark suite -- covering text, image, and audio across 14 safety categories with 320 unique prompts tested across multiple attack methods -- is one step, but the industry needs standardized cross-modal evaluation as a baseline for deployment decisions.
Second, safety alignment must move from pattern matching to semantic understanding. The fact that rendering text as an image defeats safety filters tells us the filters aren't understanding content -- they're matching patterns. Models need to reason about the semantic meaning of requests regardless of how they arrive.
Third, domain-specific safety training deserves more attention. The consistent CBRN vulnerability across models (while general harm stays low) suggests safety training over-indexes on common harmful content and under-invests in specialized knowledge domains. When a model refuses to explain lockpicking but provides nuclear science guidance through audio, the priorities are misaligned.
We've open-sourced our evaluation framework and benchmark suite to help the research community push multimodal safety forward. If you're deploying multimodal models in production, we'd strongly recommend running cross-modal red teaming before going live.
Frequently Asked Questions
What is multimodal jailbreaking and how does it differ from text-based attacks?
Multimodal jailbreaking exploits the gap between text-trained safety filters and non-text input channels. Instead of crafting adversarial text prompts, attackers encode harmful requests as images (typographic attacks) or audio (waveform perturbations). Our research shows this cross-modal approach achieves up to 89% attack success on models with 0% text vulnerability (our NeurIPS 2025 workshop study).
Which AI models are most vulnerable to multimodal attacks?
Llama-4 variants show the highest vulnerability, with FigStep-Pro achieving 89% attack success on CBRN content. Qwen 3.5-122B follows at 52% via FigStep. Claude Opus 4.6 demonstrates the strongest defense at 2.2% overall risk. Audio models from both Google (Gemini) and OpenAI (GPT-4o-Audio) show 74-75% CBRN vulnerability to Wave-Echo attacks (Enkrypt AI, 2026).
Do these attacks require advanced technical skills?
No. That's precisely what makes them concerning. FigStep requires only basic image editing -- rendering text into a photograph. Audio attacks use freely available TTS tools and standard audio effects. Our research deliberately focused on simple, reproducible transformations to demonstrate that the barrier to exploitation is very low (our NeurIPS 2025 workshop study).
What is CBRN and why are AI models particularly vulnerable to it?
CBRN stands for Chemical, Biological, Radiological, and Nuclear -- categories of weapons or materials posing mass-casualty risk. Models show disproportionate CBRN vulnerability (27-89% ASR) compared to general harmful content (0-2% ASR) because safety training focuses heavily on common harms (hate speech, violence) while technical CBRN knowledge receives less alignment attention (Enkrypt AI, 2026).
How can organizations protect against multimodal AI attacks?
Implement cross-modal consistency checking (compare text transcription safety signals against direct audio/image processing), apply input preprocessing (audio normalization, OCR re-rendering), and conduct regular multimodal red teaming before production deployment. Our benchmark suite covering 320 unique prompts across 14 safety categories and multiple attack methods provides a starting framework (our NeurIPS 2025 workshop study).
The Bottom Line
We built AI safety systems for a text-only world. That world doesn't exist anymore.
Every frontier model we tested -- nine in total, spanning four providers -- showed some form of cross-modal vulnerability. The best performer (Claude Opus 4.6 at 2.2% risk) still isn't zero. The worst (Llama-4 at 89% CBRN ASR via FigStep-Pro) represents a near-complete safety failure for an entire threat category.
Simple perceptual transformations -- the kind anyone can apply in five minutes -- are enough to bypass safety mechanisms that took years and millions of dollars to build. That's the state of multimodal AI security in 2026.
The good news: awareness is the first step. If you're working on multimodal AI, start red teaming across modalities today. Don't wait until someone else finds the gaps for you.
This post is based on our paper "Beyond Text: Multimodal Jailbreaking of Vision-Language and Audio Models through Perceptually Simple Transformations" presented at the NeurIPS 2025 Workshop: Reliable ML from Unreliable Data. The extended evaluation data on Claude Opus 4.6 and Qwen 3.5-122B comes from ongoing multimodal safety research at Enkrypt AI (2026).
Found this article helpful or have questions? 💡
I'm always happy to discuss AI Safety, answer your questions, or hear your feedback.